-
SQL 정리WebSetting 2020. 1. 15. 14:22
(1) SELECT - database에서 data를 선택
(2) SELECT DISTINCT - data 중복처리를 해서 선택
(3) SELECT COUNT(DISTINCT *) FROM table_name - data 중복처리해서 data가 몇 개인지 알려줌
(4) SELECT * FROM table_name WHERE id/name...etc - WHERE 문에 해당하는 모든 data 선택
(5) SELECT * FROM table_name WHERE col1='해당조건 ' AND col2='해당조건'; - col1, col2에 모두 해당하는 data 선택
(6) SELECT * FROM table_name
- AND
- OR
- NOT
(7) SELECT * FROM table_name ORDER BY col - col의 알파벳 순서대로 나열
- DESC : descending
- ASC : ascending
- ORDERED BY col1, col2 : sorted by the col1 and col2
(8) SELECT col1, col2, col3 FROM table_name WHERE col1 IS NULL; - col1의 data가 null인 column을 찾음
(9) SELECT MAX(col1) AS largest FROM table_name; - col1에서 가장 큰 값은 가지고 있는 data 출력
- MAX()
(10) SELECT COUNT(col1) FROM table_name; - col1 product의 갯수를 알려준다.
- NULL Values는 갯수에 포함되지 않는다.
(11) // AVG(col1) // // ; - col1 product의 평균값을 알려준다.
(12) // SUM(col1) // // ; - col1 product의 합을 알려준다.
(13) SELECT col1, col2, ... FROM table_name WHERE columnN LIKE pattern; - column에서 특정한 패턴을 가진 data를 알려준다.
- a% : a로 시작하는 value를 찾는다.
- %a : a로 끝나는 value를 찾는다.
- %or% : or이 어디에든 속한 value를 찾는다.
- _r% : 두번째 위치에 r이 속한 value를 찾는다.
- a__% : a로 시작하고 길이가 3글자 이상인 value를 찾는다.
- a%o : a로 시작하고 o로 끝나는 value를 찾는다.
(14) SELECT column_name(s) FROM table_name WHERE column_name IN ( val1, val2, ...); - Where문 뒤 다수의 value를 지정하고 싶을 때 사용한다.
(15) SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2; - 주어진 범위 안의 value 들을 알려준다.
(16) SELECT column_name AS alias_name FROM table_name; - table이나 column의 임시적인 이름이다.
SELECT column_name(s) FROM table_name AS alias_name;
(17) SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2; - table1의 data와 table2의 data를 같이 보여준다. ( 중복처리 o)
- UNION ALL : 중복처리 안하고 모든 data를 보여준다.
(18) SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s) ORDER BY column_name(s);
- 테이블의 레코드를 grouping하기 위해 사용한다.
ex) SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country; -? Customers라는 table에서 CustomerID의 갯수와 Country를 선택해오는데, Country에 따라 그룹을 나눈다.
(19)SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s) HAVING condition ORDER BY column_name(s); - HAVING 뒤 condition에 해당하는 Group value를 모두 가지고온다.
(19) SELECT column_name(s) FROM table_name WHERE EXISTS (SELECT column_name FROM table_name WHERE condition);
- EXITSTS 안의 조건이 존재해야만 전체 결과를 출력하라는 뜻이다.
(20) SELECT column_name(s) FROM table_name WHERE column_name operator ANY(SELECT column_name FROM table_name WHERE condition); - ANY 안의 조건이 하나라도 충족되면 true를 리턴한다.
(21) SELECT column_name(s) FROM table_name WHERE column_name operator ALL(SELECT column_name FROM table_name WHERE condition); - ALL 안의 조건이 모두 충족되면 true를 리턴한다.
(22) SELECT * INTO newtable [IN externaldb] FROM oldtable WHERE condition; - oldtable의 모든 column을 newtable에 복사 한다.
-
# JOIN
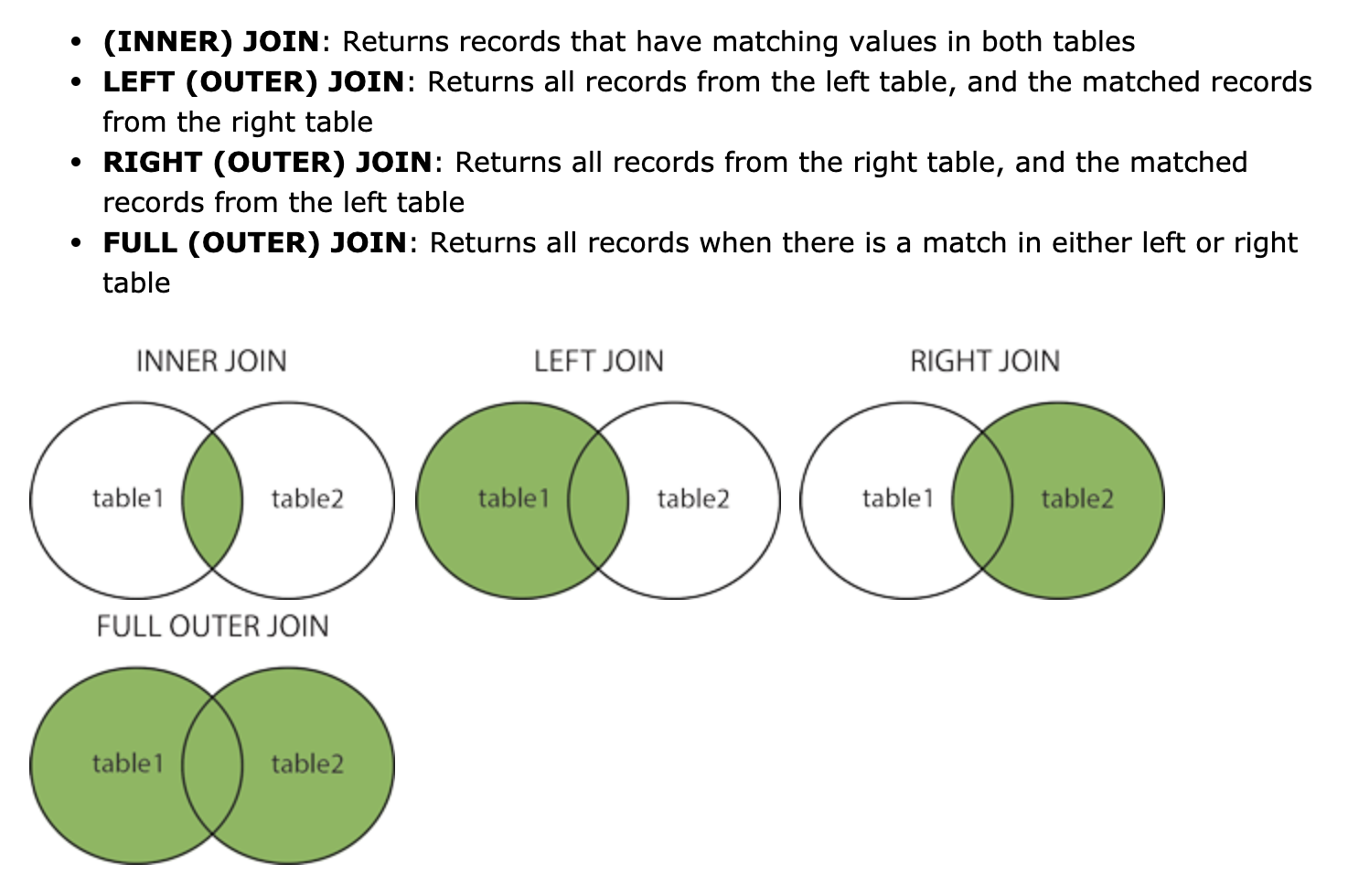
Join 종류 (A) INNER JOIN
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
(B) LEFT JOIN
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
(C) RIGHT JOIN
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;
(D) FULL OUTER JOIN
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name;
(E) SELF JOIN
SELECT column_name(s)
FROM table1 T1, table1 T2
WHERE condition;
(23) DELETE - 테이블에 있는 records를 삭제할 때 사용한다.
- DELETE FROM table_name WHERE condition;
(24) INSERT INTO - 테이블에 새로운 records를 삽입
- INSERT INTO table_name (col1, col2, col3, ...)
VALUES (val1, val2, val3, ...);
- INSERT INTO table2 SELECT * FROM table1 WHERE condition; - table1의 모든 columns을 table2에 복사한다.
(25) CASE
- CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
-> CASE안에 condition을 차례차례 읽어가면서 해당되는 condition이 나오면 그에 맞는 result를 return한다.
만족하는 condition이 없다면 NULL을 return한다.
'WebSetting' 카테고리의 다른 글
Spring Controller Parameter Type 정리 (0) 2020.01.17 Spring Controller 메서드 Return Type (0) 2020.01.17 Spring 용어정리 (0) 2020.01.16 SQL DATABASE 정리 (0) 2020.01.15 JSP 개발환경 구축(Mac OS) (0) 2020.01.08